After 17 years of experience we still run into dummy bugs in xslt (xpath in fact).
The latest one is related to order of nodes produced by ancestor-or-self axis.
Consider the code:
<xsl:stylesheet version="3.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xsl:template match="/">
<xsl:variable name="data" as="element()">
<a>
<b>
<c/>
</b>
</a>
</xsl:variable>
<xsl:variable name="item" as="element()" select="($data//c)[1]"/>
<xsl:message select="$item!ancestor-or-self::*!local-name()"/>
<xsl:message select="$item!local-name(), $item!..!local-name(), $item!..!..!local-name()"/>
</xsl:template>
</xsl:stylesheet>
We expected to have the following outcome
But correct one is
Here is why:
ancestor-or-self::* is an AxisStep. From XPath §3.3.2:
[Definition: An axis step returns a sequence of nodes that are reachable from the context node via a specified axis. Such a step has two parts: an axis, which defines the "direction of movement" for the step, and a node test, which selects nodes based on their kind, name, and/or type annotation.] If the context item is a node, an axis step returns a sequence of zero or more nodes; otherwise, a type error is raised [err:XPTY0020]. The resulting node sequence is returned in document order.
For some reason we were thinking that reverse axis produces result in reverse order. It turns out the reverse order is only within predicate of such axis.
See more at https://saxonica.plan.io/boards/3/topics/7312
XPath 3 has introduced a syntactic sugar for a string concatenation, so following:
concat($a, $b)
can be now written as:
$a || $b
This is nice addition, except when you run into a trouble. Being rooted in C world we unintentionally have written a following xslt code:
<xsl:if test="$a || $b">
...
</xsl:if>
Clearly, we intended to write $a or $b. In contrast $a || $b is evaluated as concat($a, $b). If both variables are false() we get 'falsefalse' outcome, which has effective boolean value true(). This means that test condition of xsl:if is always true().
What can be done to avoid such unfortunate typo, which is manifested in no way neither during compilation nor during runtime?
The answer is to issue informational message during the compilation, e.g. if result of || operator is converted to a boolean, and if its arguments are booleans also then chances are high this is typo, and not intentional expression.
We adviced to implement such message in the saxon processor (see https://saxonica.plan.io/boards/3/topics/7305).
It seems we've found discrepancy in regex implementation during the transformation in Saxon.
Consider the following xslt:
<xsl:stylesheet version="3.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xsl:template match="/">
<xsl:variable name="text" as="xs:string"
select="'A = "a" OR B = "b"'"/>
<xsl:analyze-string regex=""(\\"|.)*?"" select="$text">
<xsl:matching-substring>
<xsl:message>
<xsl:sequence select="regex-group(0)"/>
</xsl:message>
</xsl:matching-substring>
</xsl:analyze-string>
</xsl:template>
</xsl:stylesheet>
vs javascript
<html>
<body>
<script>
var text = 'A = "a" OR B = "b"';
var regex = /"(\\"|.)*?"/;
var match = text.match(regex);
alert(match[0]);
</script>
</body>
</html>
xslt produces: "a" OR B = "b"
while javascript: "a"
What is interesting is that we're certain this was working correctly in Saxon several years ago.
You can track progress of the bug at: https://saxonica.plan.io/boards/3/topics/7300 and at https://saxonica.plan.io/issues/3902.
For more than 25 years continues a discussion in C++ community about exceptions.
In our opinion this can only be compared with math community and their open problems like Hilbert's 23 problems dated by 1900.
In essence C++ exception discussion is about efficiency of exceptions vs status codes. This problem is not so acute in other languages (like java or C#) because those languages postulate different goals.
C++ designers have introduced a zero-overhead principle for any language feature, which is:
- If you don’t use some feature you don’t pay for it.
- If you do use it you cannot (reasonably) write it more efficiently by hand.
Exceptions comparing to status codes do not withstand this demand. This led to the fragmentation of C++ comunity where many big projects and code styles ban exceptions partially or completely.
Make no doubt that all this time people were trying to make exceptions better, and have found techniques to make them space and run time efficient to some extent, but still, old plain status codes outperform both in speed (especially in predictability of time of exception handling logic) and in code size.
We guess the solution is finally found after the quarter the century of discussion!
WG paper: Zero-overhead deterministic exceptions: Throwing values by Herb Sutter. This "paper aims to extend C++’s exception model to let functions declare that they throw a statically specified type by value. This lets the exception handling implementation be exactly as efficient and deterministic as a local return by value, with zero dynamic or non-local overheads."
In other words author suggests to:
- extend
exception model (in fact implement additional one);
- make exceptions as fast and as predicable as status codes (which virtually means designate a status code as a new exception);
Here are author's arguments:
- Status code is usually just a number, and handling an error is like to perform some
if or switch statements.
- Handling errors with status codes is predicable in time and visible in the code though it burdens the logic very much.
- Exceptions give clear separation between a control flow and error handling.
- Exceptions are mostly invisible in the code, so it's not always clear how much they add to code size and how they impact performance.
- Statistics show that exceptions add 15 to 30% to size of code, even if no exceptions are used (violation of zero-overhead principle);
- Exceptions require Run Time Type Information about types, and have no predictable memory (stack or heap) footprint (violation of zero-overhead principle).
What aurhor suggests might seem too radical but at present it's only viable solution to reestablish zero-verhead principle and to reunite two C++ camps.
Here is the approach.
- Clarify what should be considered as an exception.
- Contract violation.
Are contract violation like invalid values of arguments or invalid post conditions (unhold invariants) are exceptions or programmer's bugs?
If later then it's best to terminate, as you cannot correctly recover from bug.
-
Virtual Machine fault.
What user program can do with stack overflow?
The best according to the author it to terminate.
-
OOM - Out Of Memory error.
What is the best way to deal with OOM dyring dynamic allocation.
At present there are two operators:
new - to allocate memory dynamically and throw bad_alloc on failure.new(nothrow) - to allocate memory dynamically and return nullptr on failure.
Herb Sutter suggests to change new behavior to terminate on failure (it is very hard to properly handle bad_alloc anyway), while new(nothrow) will still allow to build code that can deal with OOM.
- Partial success
This should never be reported as an error, and status codes should be used to report the state.
- Error condition distinct from any type of success.
This is where exceptions should be used.
Statistics shows that
with such separation more than 90% of what curently is an exception will not be exception any more, so no any hidden exception logic is required: program either works or terminates.
- Refactor exception
Redefine what exception object is and how it is propagated.
It should be thin value type. At minimum it needs to contain an error code. Suggested size is up to a couple of pointers.
Compiler should be able to cheaply allocate and copy it on the stack or even in the processor's registers.
Such simple exception type resolves problems with lifetime of exception object, and makes exception handling as light as checking status codes.
Exception should be propagated through return chanel, so it's like a new calling convention that defines either function result or error outcome.
It's not our intention to quote whole the paper here. If you're interested then please read it. Here we want to outline our concerns.
- Exception payload.
This paper emphasizes that exception type should be small.
So, what to do with exception payload, if any (at least error message if it's not a static text)?
If this won't be resolved then developers will start to invent custom mechanisms like GetLastErrorMessage().
And what to do with aggregate exceptions?
We think this must be clearly addressed.
- Implemntation shift.
We can accept that most of the current exceptions will terminate.
But consider now some container that serves requests, like web container or database.
It may be built from multiple components and serve multiple requests concurently. If one request will terminate we don't want for container to terminate.
If terminate handler is called then we cannot rely on state of the application. At least we can expect heap leaks and un-released resources.
So, we either want to be able release heap and other resources per request, or we want to go down with whole process and let OS deal with it.
In the later case we need to design such containers differently: as a set of cooperative processes; OS should allow to spin processes more easily.
- VM with exceptions
There are Virtual Machines that allow exception to be thrown on each instruction (like JVM, or CLI).
You cannot tell in this case that code would never throw exception, as it can out of the blue!
Event in x86 you can have PAGE FAULT on memory access, which can be translated into an exception.
So, it's still a question whether the terminate() solution is sound in every case, and whether compiler can optimize out exception handling if it proves staticlly that no exception should be thrown.
In some code we needed to perform a circular shift of a part of array, like on the following picture:

It's clear what to do, especially in case of one element shift but think about "optimal" algorithm that does minimal number of data movemenents.
Here is what we have came up with in C#: algorithm doing single pass over data.
/// <summary>
/// <para>
/// Moves content of list within open range <code>[start, end)</code>.
/// <code>to</code> should belong to that range.
/// </para>
/// <para>
/// <code>list[start + (to - start + i) mod (end - start)] =
/// list[start + i]</code>,
/// where i in range<code>[0, end - start)</ code >.
/// </para>
/// </summary>
/// <typeparam name="T">An element type.</typeparam>
/// <param name="list">A list to move data withing.</param>
/// <param name="start">Start position, including.</param>
/// <param name="end">End position, not incuding.</param>
/// <param name="to">Target position.</param>
public static void CircularMove<T>(IList<T> list, int start, int end, int to)
{
var size = end - start;
var step = to - start;
var anchor = start;
var pos = start;
var item = list[pos];
for(int i = 0; i < size; ++i)
{
pos += step;
if (pos >= end)
{
pos -= size;
}
var next = list[pos];
list[pos] = item;
item = next;
if (pos == anchor)
{
pos = ++anchor;
if (pos >= end)
{
break;
}
item = list[pos];
}
}
}
We often deal with different SQL DBs, and in particular DB2, Oracle, and SQL Server, and this is what we have found lately.
Our client has reported a problem with SQL insert into the DB2:
- subject table has a small number of columns, but large number of rows;
- insert should attempt to insert a row but tolerate the duplicate.
The prototype table is like this:
create table Link(FromID int, ToID int, primary key(FromID, ToID));
DB2 SQL insert is like this:
insert into Link(FromID, ToID)
values(1, 2)
except
select FromID, ToID from Link;
The idea is to have empty row set to insert if there is a duplicate.
SQL Server variant looks like this:
insert into Link(FromID, ToID)
select 1, 2
except
select FromID, ToID from Link;
Client reported ridiculously slow performance of this SQL, due to table scan to calculate results of except operator.
Out of interest we performed the same experiment with SQL Server, and found the execution plan is optimal, and index seek is used to check duplicates. See:

The only reasonable way of dealing with such DB2's peculiarity, except trying to insert and handle duplicate exception, was to qualify select with where clause:
insert into Link(FromID, ToID)
values(1, 2)
except
select FromID, ToID from Link where FromID = 1 and ToID = 2;
We think DB2 could do better.
J2SE has become sole large that its different parts don't play well.
That is pitty but nothing to do. There is probably a lack of resources in Oracle to fill gaps.
So, to the point.
There is relatively new API to work with time defined in: package java.time. There is older API JAXB to serialize and deserialize beans to and from XML (and often to JSON). To JAXB viable, it should be able to deal with basic primitive types. The problem is that JAXB does not handle LocalDate, LocalTime, LocalDateTime, and ZonedDateTime out of the box.
We do understand that:
- JAXB is older and java.time is newer API; and that
- JAXB has no built-in plugin to handle new types.
But this does not help, and we should define/redefine serialization adapters using some drop in code or third party libraries. Here are these convenience adapters:
LocalDateAdapter.java
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.ZonedDateTime;
import javax.xml.bind.annotation.adapters.XmlAdapter;
/**
* An adapter for the bean properties of {@link LocalDate} type.
*/
public class LocalDateAdapter extends XmlAdapter<String, LocalDate>
{
/**
* Converts {@link LocalDate} into a string value.
* @param value a value to convert. Can be null.
* @return a string value.
*/
@Override
public String marshal(LocalDate value)
throws Exception
{
return value == null ? null : value.toString();
}
/**
* Converts a string value into a {@link LocalDate}
* instance.
* @param value a value to convert. Can be null.
* @return a {@link LocalDate} instance.
*/
@Override
public LocalDate unmarshal(String value)
throws Exception
{
if (value == null)
{
return null;
}
int p = value.indexOf('T');
if (p < 0)
{
return LocalDate.parse(value);
}
while(++p < value.length())
{
switch(value.charAt(p))
{
case '+':
case '-':
case 'Z':
{
return ZonedDateTime.parse(value).toLocalDate();
}
}
}
return LocalDateTime.parse(value).toLocalDate();
}
}
LocalDateTimeAdapter.java
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.LocalTime;
import java.time.ZonedDateTime;
import javax.xml.bind.annotation.adapters.XmlAdapter;
/**
* An adapter for the bean properties of {@link LocalDateTime} type.
*/
public class LocalDateTimeAdapter extends XmlAdapter<String, LocalDateTime>
{
/**
* Converts {@link LocalDateTime} into a string value.
* @param value a value to convert. Can be null.
* @return a string value.
*/
@Override
public String marshal(LocalDateTime value)
throws Exception
{
return value == null ? null : value.toString();
}
/**
* Converts a string value into a {@link LocalDateTime} instance.
* @param value a value to convert. Can be null.
* @return a {@link LocalDateTime} instance.
*/
@Override
public LocalDateTime unmarshal(String value)
throws Exception
{
if (value == null)
{
return null;
}
int p = value.indexOf('T');
if (p < 0)
{
return LocalDateTime.of(LocalDate.parse(value), LocalTime.MIN);
}
while(++p < value.length())
{
switch(value.charAt(p))
{
case '+':
case '-':
case 'Z':
{
return ZonedDateTime.parse(value).toLocalDateTime();
}
}
}
return LocalDateTime.parse(value);
}
}
LocalTimeAdapter.java
import java.time.LocalDate;import java.time.LocalTime;
import javax.xml.bind.annotation.adapters.XmlAdapter;
/**
* An adapter for the bean properties of {@link LocalTime} type.
*/
public class LocalTimeAdapter extends XmlAdapter<String, LocalTime>
{
/**
* Converts {@link LocalTime} into string value.
* @param value a value to convert. Can be null.
* @return a string value
*/
@Override
public String marshal(LocalTime value)
throws Exception
{
return value == null ? null : value.toString();
}
/**
* Converts a string value into a {@link LocalTime} instance.
* @param value a value to convert. Can be null.
* @return a {@link LocalTime} instance.
*/
@Override
public LocalTime unmarshal(String value)
throws Exception
{
return value == null ? null : LocalTime.parse(value);
}
}
To make them work either field/properties or package should be annotated with JAXB xml adapters.
The simplest way is to annotate it on package level like this:
package-info.java
@XmlJavaTypeAdapters(
{
@XmlJavaTypeAdapter(value = LocalDateAdapter.class, type = LocalDate.class),
@XmlJavaTypeAdapter(value = LocalTimeAdapter.class, type = LocalTime.class),
@XmlJavaTypeAdapter(value = LocalDateTimeAdapter.class, type = LocalDateTime.class)
})
package com.nesterovskyBros.demo.entities;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.LocalTime;
import javax.xml.bind.annotation.adapters.XmlJavaTypeAdapter;
import javax.xml.bind.annotation.adapters.XmlJavaTypeAdapters;
We've run into following java function that models some variation of NULL arithmetic:
public static Long add(Long value1, Long value2)
{
return value1 == null ? value2 : value2 == null ? value1 : value1 + value2;
}
When this function runs the outcome is different from what we have expected.
Here is a quiz:
What is outcome of add(1, 2):
3;null;- other.
What is outcome of add(3, null):
3;null;- other.
What is outcome of add(null, 4):
null;4;- other.
What is outcome of add(null, null):
null;0;- other.
Our assumptions were:
add(1, 2) == 3;add(3, null) == 3;add(null, 4) == 4;add(null, null) == null;
Java works differently:
add(1, 2) == 3;add(3, null) throws NullPointerException;add(null, 4) throws NullPointerException;add(null, null) throws NullPointerException;
The problem is with compile time type of ternary ?: operator. Compiler decides it's long, while we intuitively expected Long. Java casts null to long (which results into NPE), and then to Long.
Correct code would be:
public static Long add(Long value1, Long value2)
{
if (value1 == null)
{
return value2;
}
else if (value2 == null)
{
return value;
}
else
{
return value1 + value2;
}
}
This version does not cast anything to long, and works as we originally expected.
Honestly, we're a bit anexious about this subtle difference of if-then-else and ?: operator.
Don't you think there is something wrong with world map according to Yandex?
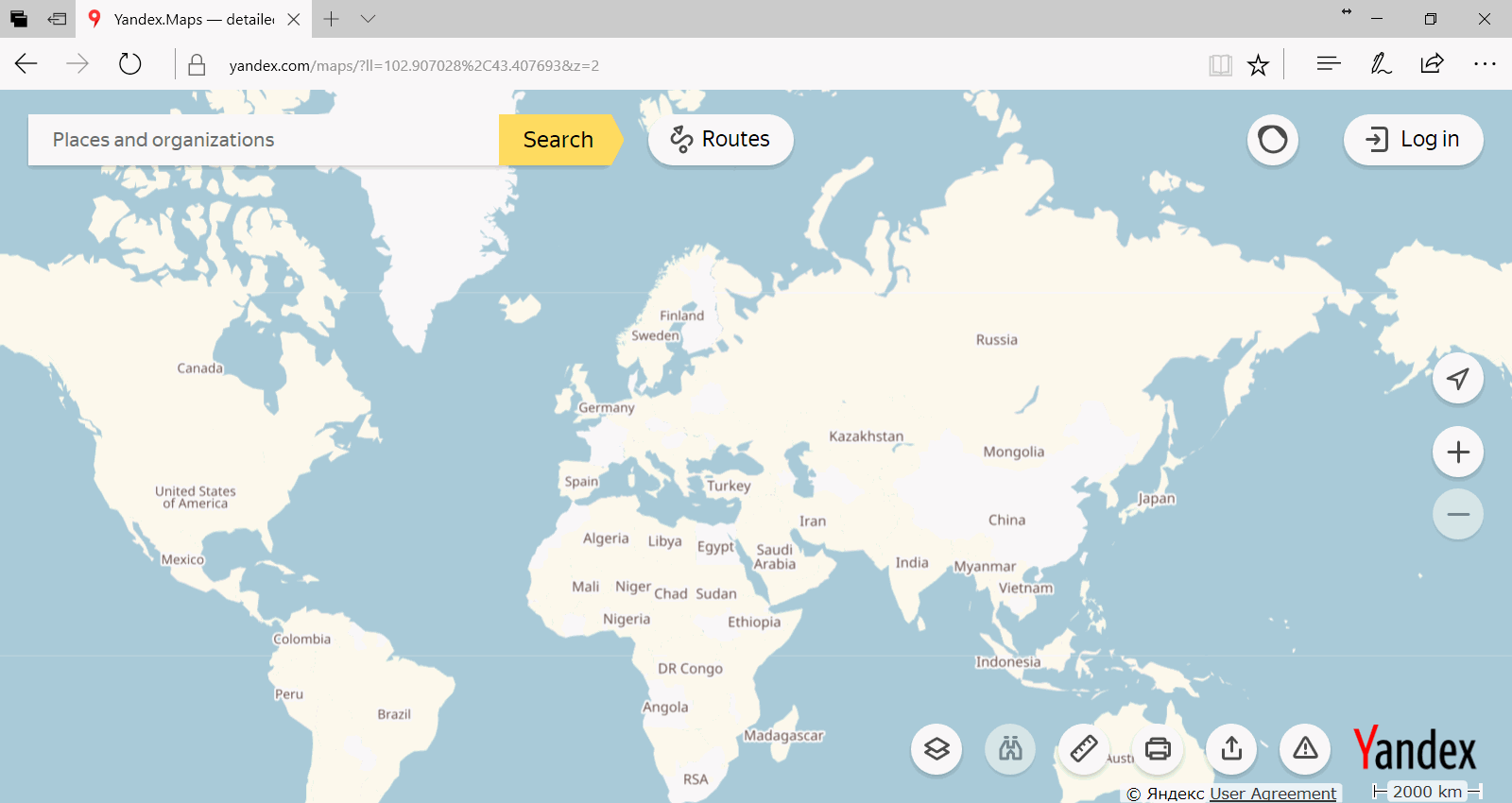
They seems have optimized something in Black Sea region.
Today we wanted to write some code in java that performs some or the other action depending on a condition. At the same time if some action fails we wanted to fall back to the other action.
We've written it like this:
switch(boolean_expression)
{
case true:
{
try
{
// Some actions.
break;
}
catch(Exception e)
{
// Fall back to false route.
}
}
case false:
{
// Other actions.
break;
}
}
The fun part is that it's not valid java code.
Why?
The answer can be found in spec: 14.11. The switch Statement
The type of the Expression must be char, byte, short, int, Character, Byte, Short, Integer, String, or an enum type (§8.9), or a compile-time error occurs.
But why?
Who knows...
Sure there are workarounds, even with switch, but it just not justified restriction...
Saxon-HE 9.8.0-3 is out but still problems are there.
See Incorrect behavior in Saxon-HE-9.8.0-3 (maven).
Another problem is that we see that something has propably happened with tail call optimization. Code that was working earlier now give an error:
err:SXLM0001: Too many nested function calls. May be due to infinite recursion.
We have to figure out how to build a simple TC for Michael Kay to test it.
See Saxon-HE 9.8.0-3 Tail Calls.
We've found that there is a Saxon HE update that was going to fix problems we mentioned in the previous post, and decided to give it a second chance.
Now Saxon fails with two other errors:
We shall be waiting for the fixes. Mean time we're back to version 9.7.
Finally, Saxon 9.8 is out!
This means that basic xslt 3 is available in the HE version.
Update: as usually, each new release has new bugs...
See https://saxonica.plan.io/boards/3/topics/6809
We have found that Saxon HE 9.7.0-18 has finally exposed partial support to map and array item types. So, now you can encapsulate your data in sequence rather than having a single sequence and treating odd and even elements specially.
Basic example is:
<xsl:stylesheet version="3.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:t="t"
xmlns:map="http://www.w3.org/2005/xpath-functions/map"
exclude-result-prefixes="xs t map">
<xsl:template match="/">
<xsl:variable name="map" as="map(xs:string, xs:string)" select="
map
{
'Su': 'Sunday',
'Mo': 'Monday',
'Tu': 'Tuesday',
'We': 'Wednesday',
'Th': 'Thursday',
'Fr': 'Friday',
'Sa': 'Saturday'
}"/>
<xsl:message select="map:keys($map)"/>
</xsl:template>
</xsl:stylesheet>
A list of map functions can be found here http://www.w3.org/2005/xpath-functions/map/, though not all are available, as Saxon HE still does not allow inline functions.
P.S. From the development perspective it's a great harm that Saxon HE is so limited. Basically limited to xslt 2.0 + some selected parts of 3.0.
|